尾崎安範
(Yasunori Ozaki)
このページでは研究活動などをまとめています。
生成AIと人間・ロボットインタラクションを中心に、人の創作や行動を理解し、実世界のサービスやプロダクトにつなげる研究開発に取り組んでいます。
- 研究テーマ: 生成AI、動画生成AI、人間・ロボットインタラクション
- 実用化・助成: 公開モデル、サービス、研究助成
- 発表文献: ジャーナル、査読付き会議、その他の文献
- 学術・公益・広報活動: 査読、講演、メディア掲載、特許
研究テーマ
近年は、生成AIを創作やプロダクトに接続する研究開発に重点を置いています。 その前提として、特定の作風を模倣する生成AIの技術面と倫理面、日本語圏のクリエイターが使いやすい動画生成AI、実世界で人と自然に関わるロボットの研究に取り組んできました。
- 生成AIと創作
- 作風模倣、透明性、クリエイターへの利益還元、社会的受容性を扱います。
- 動画生成AI
- 日本語入力、効率的な基盤モデル、公開モデル、サービス化までを扱います。
- 人間・ロボットインタラクション
- 通行者の状態推定、対話開始、呼びかけの不快感低減を扱います。
特定の作風を模倣する画像・動画生成AIの技術面と倫理面の研究 [16, 17]
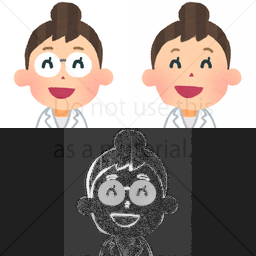
個人的な研究の末、拡散モデルやフローといった高度な画像生成AIが特定の作風を模倣できることを発見しました。
本研究では、その模倣が社会に与える影響を中長期的(2026年現在では4年経過)に調べています。
一つの応用として、AIいらすとやがあります。これはいらすとやを運営するみふねたかしさんの協力のもと、
いらすとやの作風を模倣したAIで作家に利益還元するという現象の活用法を示しました。
現在も倫理的な研究を進めています。
日本語入力にネイティブ対応した動画生成AIの研究開発 [19]

日本語圏のクリエイターが利用しやすい動画生成AIを目指し、テキストから動画を生成する基盤モデルを研究開発しています。
2025年には、GENIACの支援を受けて、商用利用可能なApache-2.0ライセンスの学習済み重みと推論コードを含む
AIdeaLab VideoJPを公開しました。
本モデルは日本語と英語の入力に対応し、Rectified Flow Transformerを用いた動画生成モデルとして開発しました。
技術報告では、日本語入力に対するFVDとアラインメントの評価を行い、日本語圏向け動画生成モデルとしての有効性と課題を整理しています。
2026年には、動画生成分野にSparse Mixture of Expertsを適用した
AIdeaLab VideoMoEも公開し、
日本語対応、効率化、クリエイター支援を軸にした動画生成AIの研究を進めています。
これらの研究開発は、テキストや画像からアニメ風動画を生成するAIサービス
AnimeGenにも活用されており、
基盤モデルの開発からプロダクト化まで一貫して取り組んでいます。
空気を読むロボット -ロボット展示員は通行人に不快感を与えず、こちらに興味を引かせられるのか?- [12]

本研究では、コミュニケーションロボットが通行人に不快感を与えずに挨拶をして注意を引く方法を開発することを目的としています。
近年、人ではなくコミュニケーションロボットが受付や案内、展示などのサービスを行うことが多くなっています。
例えば、ロボットの展示者は、ロボットの所有者が宣伝している商品を説明することができます。
しかし、ロボットの突然の挨拶は、通行人を驚かせ、通行人に不快感を与える可能性があります。
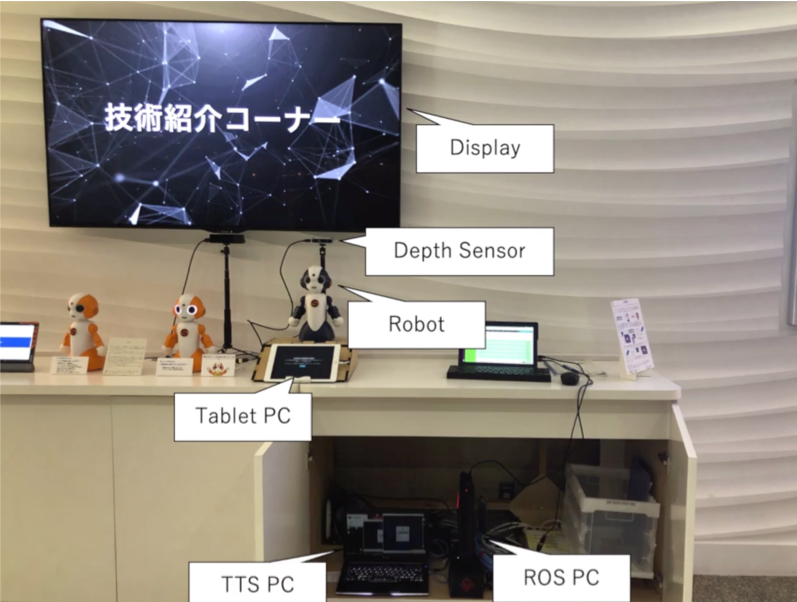

そのため、コミュニケーションロボットは、通行人が直面する状況に応じて、自分のマナーを適応させる必要があります。
私たちは、この要求を満たすための手法を、関連研究の結果に基づいて開発しました。
本研究では、ロボットが通行人に不快感を与えることなく、挨拶をして注意を引くことができる手法「ユーザ中心強化学習」を提案しています。
オフィスのエントランスというフィールドでの実験の結果、本手法がこの要求を満たすことが実証されました。
通行者の行動モデルに基づいてサービス利用を予測するシステム[9][10]
本研究の目的は,ロボットの前を通りかかった歩行者がそのロボットが提供するサービスを利用するか、その意志決定を予測する方法を実現することです。
また、その手法がもたらす心理的影響を明らかにすることです。
この目的に達成するために、サービスを利用する人間の行動を従来の研究から数理モデル化し、センサデータから人間の行動をモデルに合致するかシミュレートする方法を取りました。
具体的には、センサデータから歩行者の位置や顔向きを推定し、その位置や顔向きから人間の状態を予測、人間の状態が利用している状態にあると予測し、そうでない場合、利用しないと予測する方法を取ります。
検証実験の結果、統制された環境では、利用意志をすべて正確に予測でき、実環境に基づいたシミュレーションでは他の手法に比べ高い精度で利用意志を予測できることが統計的にわかりました。また、この手法に基づいて、利用意志があると推定される歩行者に音声で呼びかけた結果、他の手法に比べ、不快感を与えにくい特徴があることが新たにわかりました。
通行者の行動モデルに基づいてサービス利用を促すバーチャルエージェント[2][8]

本研究の目的は,サービス利用を促すバーチャルエージェントを備えたインタラクティブサイネージを実現することです。
この目的に達成するために、バーチャルエージェントが通行者に利用を音声にて呼びかけるインタラクティブサイネージを構築しました。
サイネージを利用する割合とサイネージに対する通行者の印象の二つの観点からサイネージの有効性を現場にて実験により検証しました.
検証実験の結果,エージェントが呼びかけを行わない場合に比べ,エージェントの横を通過している通行者に対してエージェントが呼びかけを行うと
エージェントとインタラクションする通行者の割合は多くなる傾向が見られました。
実用化・助成
研究開発の実用化
研究助成
代表
発表文献
ジャーナル/論文誌
- [15] Yuki Okafuji, Yasunori Ozaki, Jun Baba, Junya Nakanishi, Kohei Ogawa, Yuichiro Yoshikawa, Hiroshi Ishiguro, “Behavioral assessment of a humanoid robot when attracting pedestrians in a mall,” International Journal of Social Robotics, 2022 (preprint: arXiv)
- [3] Yusuke Sugano, Yasunori Ozaki, Hiroshi Kasai, Keisuke Ogaki and Yoichi Sato, "Image Preference Estimation with a Data-driven Approach: A Comparative Study between Gaze and Image Features," Journal of Eye Movement Research, vol. 7, num. 3, 2014.
査読付き国際会議/国内会議
- [14] Yuki Tamaru, Yasunori Ozaki, Yuki Okafuji, Jun Baba, Junya Nakanishi, Yuichiro Yoshikawa, "3D Head-Position Prediction in First-Person View by Considering Head Pose for Human-Robot Eye Contact", HRI 2022 (LBR Accepted, preprint: arXiv)
- [13] Okafuji, Yuki and Ozaki, Yasunori and Baba, Jun and Kitahara, Asano and Nakanishi, Junya and Ogawa, Kohei and Yoshikawa, Yuichiro and Ishiguro, Hiroshi, "Please Listen to Me: How to Make Passersby Stop by a Humanoid Robot in a Shopping Mall", HRI 2020 (LBR, acceptance rate: 88%)
- [12] Yasunori Ozaki, Tatsuya Ishihara, Narimune Matsumura, Tadashi Nunobiki, "Can User-Centered Reinforcement Learning Allow a Robot to Attract Passersby without Causing Discomfort?", IROS 2019 (acceptance rate: 44.9%, preprint: arXiv )
- [10] Ozaki, Yasunori; Ishihara, Tatsuya; Matsumura, Narimune; Nunobiki, Tadashi; Yamada, Tomohiro, "Decision-Making Prediction for Human-Robot Engagement between Pedestrian and Robot Receptionist", IEEE RO-MAN 2018 (Oral, acceptance rate: 40-50%)
- [7] Ozaki, Yasunori, Aoki, Ryosuke, Kimura, Toshitaka,.Takashima, Youichi Yamada, Tomohiro, "Characterizing Multi EMG Channels Using Non-Negative Matrix Factorization for Driver Swings", IEEE EMBC 2016 (Poster, acceptance rate: 30-50%)
- [11] 矢野裕季, 東風上奏絵, 中野将尚, 尾崎安範, 佐藤大貴, 倉橋孝雄, 越地弘順,肥後直樹, 椿俊光, 布引純史(NTT), "電動車椅子のための実環境における歩行者回避領域の評価手法", 第24回ロボティクスシンポジア, pp.299-300, 2019
その他の文献
- [19] 尾崎安範,石原昌文,富平準喜, "日本語入力にネイティブ対応したテキストからの動画生成のフルスクラッチ開発と公開", Jxiv, 2025 (Jxiv)
- [18] 尾崎安範,三嶋隆史,富平準喜, "CommonArt ~ 国産大規模言語モデルによる透明性の高い画像生成用拡散トランスフォーマー ~", PRMU, 2024 (Jxiv)
- [17] 尾崎安範, "特定の作家の作風に酷似した顔アイコンを創作する符号統合拡散モデル ~ 創作するイラスト深層生成モデルを活用する受容性の調査 ~", PRMU, 2022
- [16] 尾崎安範, "特定の作家の作風に酷似した顔アイコンを創作する拡散モデル(仮題)", preprint v2 v1, analysis
- [9] 尾崎安範, 石原達也, 松村成宗, 布引純史, "受付ロボットに対する通行者が抱く対話意志の予測とその心理的効果", CNR 2018
- [8] 尾崎安範, 石原達也, 前田航洋, 鏡明彦, 松村成宗, 望月崇由, 布引純史, 山田智広, "通行者の行動モデルに基づいてサービス利用を促すバーチャルエージェントを備えたインタラクティブサイネージ", CNR 2017
- [6] 尾崎安範、青木良輔、木村俊貴、高嶋洋一、山田智広、"ゴルフスイングにおける筋活動センサデータからの非負値行列因子分解による特徴抽出" MBE, 2016
- [5] 尾崎安範, 青木良輔, 松村成宗, 高嶋洋一, 山田智広, "運動学習を促進する力触覚インタラクション技術に関する検討", クラウドネットワークロボット研究会(CNR), 2015
- [4] 尾崎安範, 菅野裕介, 佐藤洋一, "視線情報と画像特徴に基づく画像の選好推定", パターン認識・メディア理解研究会(PRMU), 2014
- [2] 尾崎安範, "目と目で通じ合う初音ミク -視線と微笑みのインタラクション-," あの人の研究論文集, Vol.3, No.1, 2012
- (ネタ論文ですが、査読付きで採択率は約30%でした。投稿者はほぼ東大生でした。)
- [1] 尾崎安範, 出口大輔, 高橋友和, 井手一郎, 村瀬 洋, "印象に基づく属性による顔画像の検索に関する検討," 電子情報通信学会 総合大会, 2012
学術・公益・広報活動
学術的活動
- 座長経験: AVIC 2021 Session Chair
- 査読経験: MIRU 2025, MIRU 2024, MIRU 2023, MIRU 2022 (査読賞), ICPR 2022, HAI 2021, 電気学会 論文誌
- 招待講演: エンタテイメント情報学 2023(福知山公立大学), 信号とシステム 2022(阪大)
公益的活動
- "AI時代の知的財産権検討会(第2回)", 内閣府, 2023, 内閣府のサイトへ
広報活動
メディア掲載
- "日本発のアニメ生成AI「AnimeGen」無料ベータテスト開始", ASCII, 2025 ASCIIのサイトへ
- "日本初の日本語対応の動画生成AI基盤モデル「AIdeaLab VideoJP」無償公開! 商用利用可、ライセンスに考慮しゼロから動画学習", CGWORLD, 2025, CGWORLDのサイトへ
- "キャプション付き画像のデータ約1000万枚、AI Picassoが無償公開 「著作権に配慮、AIモデル開発に利用して」", ITmedia, 2024, ITmediaのサイトへ
- "商用利用OKの画像生成AI「Emi」公開 クリエイターと対話して開発、無断転載画像不使用", ITmedia, 2023, ITmediaのサイトへ
- "「いらすとや」風画像を無限に生成 「AIいらすとや」商用利用可に 有料サービス化", ITmedia, 2023, ITmediaのサイトへ
- "ロボットが困っていると通行人は立ち止まる。サイバーエージェントと阪大が明らかにしたこと", ニュースイッチ, 2022, ニュースイッチのサイトへ
- "ロボットが呼び込み 大阪で実証実験、商業施設を活用", 日本経済新聞電子版, 2019, 日経新聞のサイトへ
- "夜の東京でロボ実験、小池都知事が視察 調理や運搬", 日本経済新聞電子版, 2019, 日経新聞のサイトへ
- "A new approach allows robots to attract passersby without causing them discomfort", Tech Xplore, 2019,ニュースサイトへ
- "NTT、「おもてなし」の最新技術を研究・開発中、2020年に向けて", INTERNET Watch, 2015, ニュースサイトへ
- 補足: パワードスーツのくだりが私の担当になります。
プレスリリース
- "AI Lab、ロボティクス分野の主要ジャーナル「International Journal of Social Robotics」にて論文採択 ー 自律声掛けロボットにおける対話開始手法を検討 ー", サイバーエージェント, サイバーエージェントのページへ
- "報道発表資料 ロボットが案内すると商品の売上がアップ!?南港ATCでロボットによる接客・広告の実証実験を実施します", 大阪市, 大阪市のページへ
公開された特許
- [特許9] 尾崎 安範 他, "情報出力装置、方法およびプログラム", 特開2020-24517
- [特許8] 尾崎 安範 他, "情報出力装置、方法およびプログラム", 特開2019-128910
- [特許7] 尾崎 安範 他, "情報出力装置、方法およびプログラム", 特開2019-128557
- [特許6] 尾崎 安範 他, "行動状態推定装置、行動状態推定方法及びそのプログラム", 特開2019-087175
- [特許5] 尾崎 安範 他, "筋活動可聴化装置、筋活動可聴化方法およびプログラム", 特開2018-023445
- [特許4] 尾崎 安範 他, "筋活動解析装置、方法およびプログラム", 特開2018-015405
- [特許3] 尾崎 安範 他, "筋活動推定装置、方法およびプログラム", 特開2018-015408
- [特許2] 尾崎 安範 他, "力感フィードバック装置", 特開2018-020002
- [特許1] 杉山 弘晃, 目黒 豊美, 大和 淳司, 山田 智広, 望月 崇由, 松元 崇裕, 尾崎 安範, 吉川 雄一郎, 石黒 浩, "対話方法、対話システム、対話装置、およびプログラム", 特開2017-207693
ポートフォリオ
学生時代や社会人で作成した主な作品の概要をスライドにまとめました。
連絡先
E-mail: ozaki.yasunori (at) outlook.com
(at)を@に変更してください。
(at)を@に変更してください。